Spatial Filter
The Data | Data | Spatial Filter command can be used to spatially filter the X, Y and Z coordinates. This can be useful when pre-filtering data before creating a post map, variogram, or grid file and saving the data for use in other programs in the future. The spatial filter can be used to allow duplicate removal and arbitrary exclusion with a mathematical expression. Spatial filter specifications are made in the Spatial Filter dialog.
Spatial Filter Dialog
Click the Data | Data | Spatial Filter command or the  button in the worksheet to open the Spatial Filter dialog.
button in the worksheet to open the Spatial Filter dialog.
|
|
|
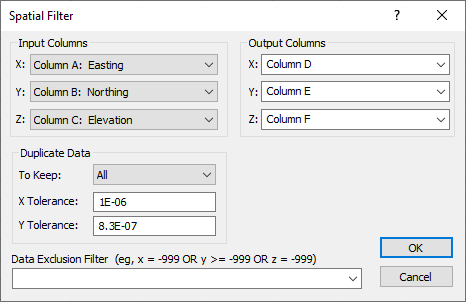
Specify custom options to spatially filter data in the Spatial Filter dialog. |
Input Columns
The Input Columns section indicates the original X, Y and Z columns. Select the Input Columns in the X, Y, and Z lists. Click the arrow button to see the list. The Z column is optional and can be set to None if the operation is for 2D (X, Y) coordinates only. If the Z Input Columns is set to None, the Z Output Columns is not available.
Output Columns
The Output Columns section indicates the location where the filtered results of the X, Y and Z columns are written. Select the Output Columns in the X, Y, and Z lists. Click the arrow button to see the list. If the Z Input Columns is set to None , the Z Output Columns is not available.
Filtered results are written to the original row and new worksheet columns as specified in the Output Columns group. New data are added to the bottom of the worksheet to ensure that the source and target points stay aligned on the same row.
Duplicate Data
The Duplicate Data section contains methods for defining and handling duplicate data points. Duplicate data are two or more data points having nearly identical X, Y coordinates (Z values may vary for these X, Y coordinates). Select the action for duplicate data in the To Keep list. Enter the X Tolerance and Y Tolerance. If a point is deleted (due to duplication or exclusion), the output cell is left blank.
To Keep
Duplicates are determined by moving from the lowest X value to the highest X value. A datum only belongs to one set of duplicates. The To Keep options specify which duplicate data points to keep and which to delete in each set of duplicate points. Specify All, None, First, Last, Minimum X, Maximum X, Median X, Minimum Y, Maximum Y, Median Y, Minimum Z, Maximum Z, Median Z, Sum, Average, Midrange, or Random from the To Keep list.
|
All |
Do not delete any duplicates. |
|
None |
Eliminate all of the duplicates. |
|
First |
Keep the first point, as defined by the order in the data file, from each set of duplicates. |
|
Last |
Keep the last point, as defined by the order in the data file, from each set of duplicates. |
|
Minimum X |
Keep the point with the minimum X coordinate. |
|
Maximum X |
Keep the point with the maximum X coordinate. |
|
Median X |
Keep the point with the median X coordinate. |
|
Minimum Y |
Keep the point with the minimum Y coordinate. |
|
Maximum Y |
Keep the point with the maximum Y coordinate. |
|
Median Y |
Keep the point with the median Y coordinate. |
|
Minimum Z |
Keep the point with the minimum Z value. |
|
Maximum Z |
Keep the point with the maximum Z value. |
|
Median Z |
Keep the point with the median Z value. |
|
Sum |
Create an artificial datum at the centroid of the duplicate points with a Z value equal to the sum of the duplicate set's Z values. |
|
Average |
Create an artificial datum at the centroid of the duplicate points with a Z value equal to the average of the duplicate set's Z values. |
|
Midrange |
Create an artificial datum at the centroid of the duplicate points with a Z value equal to the midrange of the duplicate observations' Z values halfway between the minimum Z and the maximum Z. |
|
Random |
Keep a single randomly selected representative point. |
X and Y Tolerance
In addition to the To Keep options there are X Tolerance and Y Tolerance options. For example, two points, A and B are duplicates if:
|
|

Using this definition, it is possible for points A and B to be "duplicates," for point B and C to be "duplicates," but for A and C to not be "duplicates."
Data Exclusion Filter
The Data Exclusion Filter allows a Boolean expression to specify how to exclude data. The Data Exclusion Filter can be used with any column in the worksheet that contains numbers. Columns in the worksheet that contain text or columns that are empty will not be excluded by the Data Exclusion Filter.
To use one of the X, Y, or Z columns, use X, Y, or Z in the Data Exclusion Filter . To use another column from the worksheet, use _A, _B, _C, etc. The underscore is required when specifying a worksheet column.
For example:
|
X=-999 or Y=-999 or Z=-999 |
Excludes any data with a -999 value in either the X, Y, or Z columns. |
|
X<10 or X>20 or Y<10 or Y>20 |
Excludes all data except for points in the range 10 to 20 for both the X and Y directions. |
|
Z < 0.0 |
Excludes any triplet with Z value less than 0.0. |
|
_A > 10 |
Excludes any row in the worksheet that contains a value greater than 10 in column A. |
|
Z < 0 AND _D = -999 |
Excludes any triplet with Z value less than 0.0 and whose row in the worksheet contains a value in column D equal to -999. |
Boolean expressions, used by Grids | New Grid | Function, Grids | Calculate | Math, Grid | Data, and Grid | Variogram, include:
- logical operators (and, or, xor, not)
- comparison operators (=, <>, <, >, <=, >=)
- the IF function - for example IF(condition,
The words AND, OR, XOR, NOT, and IF are reserved keywords and may not be used as variable names.
To use a stored function, click the ![]() next to the current function. This will display the ten most recent functions used. The functions are stored in the registry, so the equations are stored between Surfer sessions. You can also start typing the function in the function box. If the function is in the ten function history, the entire function will auto-complete.
next to the current function. This will display the ten most recent functions used. The functions are stored in the registry, so the equations are stored between Surfer sessions. You can also start typing the function in the function box. If the function is in the ten function history, the entire function will auto-complete.
For example, consider the case of ignoring data outside of a grid. The original grid X Maximum is 50, but the grid X Maximum is reset to 40. To limit the search to data with X values less than 40, use the Data Exclusion Filter by entering X > 40 into the Data Exclusion Filter text box. This tells Surfer to exclude all data with X values greater than 40.
Consider a second case where data contains a numerical identifier in column D. When the value in this column is equal to -999, the data point is considered inaccurate and should not be used when gridding. To grid only those data where column D is not equal to -999, exclude column D with the Data Exclusion Filter by entering _D = -999 into the Data Exclusion Filter text box. This excludes all rows of data where column D contains the value -999.