Data Metrics
The collection of data metrics gridding methods creates grids of information about the data on a node-by-node basis. The data metrics gridding methods are not, in general, weighted average interpolators of the Z values. For example, you can obtain information such as:
-
The number of data points used to interpolate each grid node. If the number of data points used are fairly equal at each grid node, then the quality of the grid at each grid node can be interpreted.
-
The standard deviation, variance, coefficient of variation, and median absolute deviation of the data at each grid node. These are measures of the variability in space of the grid, and are important information for statistical analysis.
-
The distance to the nearest data point. For example, if the XY values of a data set are sampling locations, use the Distance to Nearest data metric to determine locations for new sampling locations. A contour map of the distance to the nearest data point, quantifies where higher sampling density may be desired.
Data Metrics Options Dialog
In the Grid Data dialog, specify Data Metrics as the Gridding Method and click the Next button to open the Grid Data - Data Metrics - Options dialog.
|
|
|
Select the metric to interpolate in the Grid Data - Data Metrics - Options dialog. |
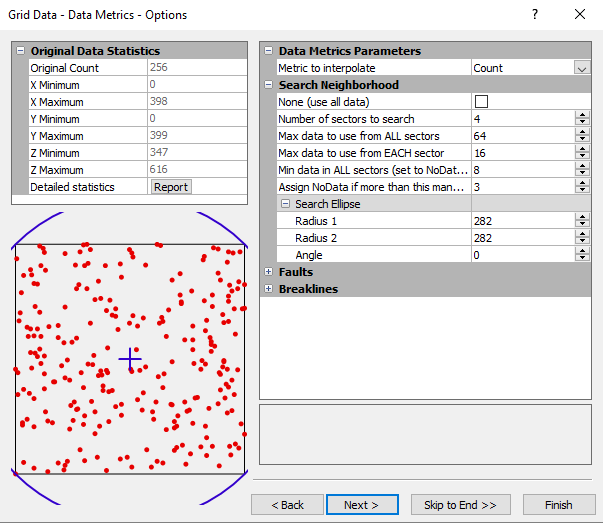
Data metrics use the local data set including breaklines, for a specific grid node for the selected data metric. The local data set is defined by the search parameters. These search parameters are applied to each grid node to determine the local data set. In the following descriptions, when computing the value of a grid node (r, c), the local data set S(r, c) consists of data within the specified search parameters centered at the specific grid node only. The set of selected data at the current grid node (r,c), can be represented by S(r,c), where
|
|
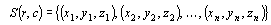
where n = number of data points in the local data set.
The Z(r,c) location refers to a specific node within the grid.
Data Metrics Descriptions
There are five groups of data metrics:
Planar Grids
Data metrics is used to provide information about your data. After information is obtained from data metrics, it is likely you will grid the data again using one of the other gridding methods. When using data metrics, you will usually want to use the same output grid geometry, search, breakline, and fault parameters as when you grid the data using another gridding method.
When using some data metrics, a horizontal planar or sloping planar grid is generated. This is usually a result of the selected search method. For example, consider using Demogrid.dat and the Count data metric. The Count data metric determines the number of data points used in determining the grid node value. Since Demogrid.dat contains 47 data points, No search (use all of the data) is the default search method. Using No search (use all of the data) means for each calculated grid node, all 47 points are used in determining the grid node value. The resulting data metric grid is horizontal planar because all grid nodes have a Z value of 47. The grid report shows both the Z minimum and the Z maximum as 47.
Other data metrics can yield similar results. For example, if the search radius is large enough to include all of the data using Terrain Statistics, the moving average is computed with such a large search radius that the resulting grid will be a planar surface at the data average. When interpreting data metrics results, keep the gridding parameters and the data metrics calculation approach in mind.
Search Neighborhood
Specify search rules. For more information about search rules, see Search.
Breaklines and Faults
Specify a breakline and/or fault. For more information, see Breaklines and Faults. Breaklines and faults are supported when creating a grid surface (XYZ data). Breaklines and faults are not supported when creating a grid volume (XYZC data).